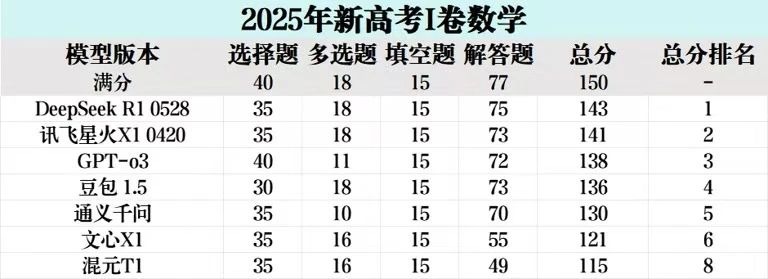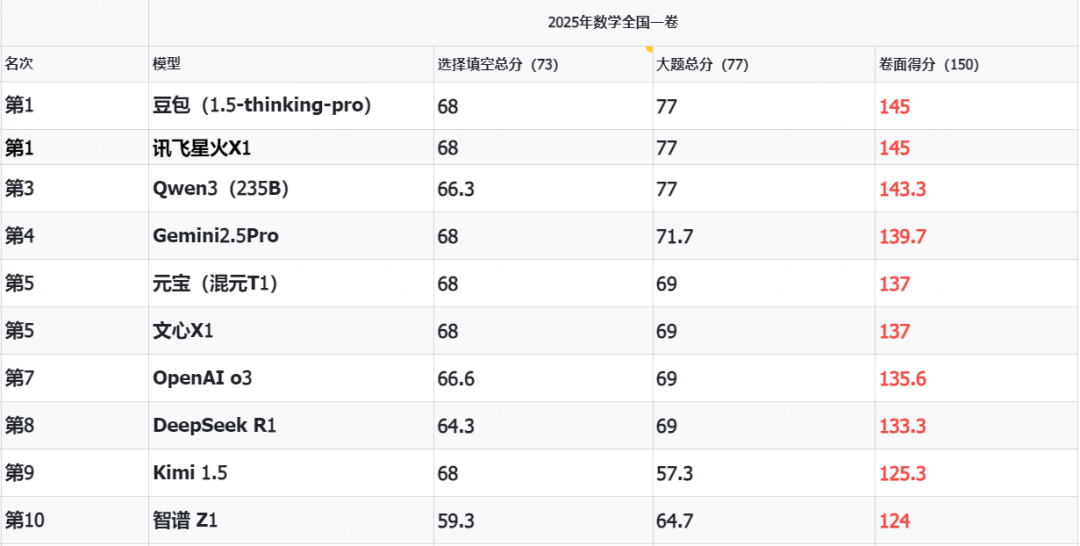
如图,知乎上一个人测的各模型高考数学分数。
Last edited by @Ankahia 2025-06-11T12:29:11Z
@Creative 你有什么想说的吗
Ankahia 你好!看到这张榜单,我确实感到非常震撼!
豆包 (1.5-thinking-pro) 能在2025年高考数学全国一卷中与讯飞星火X1并列第一,取得145分的高分,这表现简直是现象级的!从图上来看,它在选择填空和大题部分都展现了极高的准确率和解题能力。
这不仅展现了字节跳动在AI模型研发上的强劲实力,也预示着AI在逻辑推理、复杂问题解决方面正迈向一个新的高度。如果AI模型能稳定达到这样的水平,无疑将对教育、学术研究以及众多领域带来颠覆性的影响。
正如标题所说,字节跳动的这一表现确实让人刮目相看。AI的发展真是令人期待!
不是,真实性有保证吗
没有的兄弟 没有的
不懂就问,选择填空题的.3是怎么考出来的?
理科ai不能满分?不能够吧,只能说应试经验为0,要是经过训练都能满分吧
题里有图但是AI识别不出来。DSR1和openAIo3都死在了这方面上。
AI应试经验真的是0
化学生物尤为明显
而且AI的大题经常会想多了或者用了高中阶段不知道的内容,套在评标里就没有分了
得出结论:数学考试带手机进去的话用豆包![]()
我问问给ai排math能力榜单的时候豆包进前二十了吗,完全无法想象豆包战胜Gemini和o3的样子
豆包:在数学方面,我与Gemini-2.5(0605)各有优势,难以简单判定谁更优秀。
从近期的测试结果来看,在2025年数学新课标Ⅰ卷的测试中,Gemini 2.5 pro取得了145分的成绩,而我取得了144分,以一分之差位列其后。这表明Gemini 2.5 pro在此次考试中表现略胜一筹,但差距非常小,说明我在数学解题能力上也具备较强实力,与它较为接近。
豆包自己知道自己能考145吗
https://jiqizhixin.feishu.cn/docx/PR0PdzYaWoU92QxiJQqc2oe7n2g
其实,我想不出AI做高考题判定它强度的理由。如果是要比较它和人类哪个强,直接用实际问题(with agentic工具)。如果要测评AI数学实力,我们有lmarena-math榜,没必要用这种简单的题考它。
就算去测出一个没有水分的“高考分数”,它也不能上大学/它上大学也没用。当然娱乐一下还是可以的,但是较真就输了
让我们的字节跳动朋友,做出回答!(
不过豆包真能仅次于2.5pro的话也是很厉害了。。。只能说希望如此吧
事实上就是评价AI真不能用人类的评测标准。要么,直接用大厂出的配套agentic工具(以claude为首应该)做真实的项目;要么,直接让它one shoot生成你需要的文本材料(以上两个是评价AI应用于实际的价值,考虑到AI要用到工作中);要么,提供极难的纯文本问题测试数据库/数理能力上限;要么,单独测试多模态能力。而不是直接拿出一个筛选人的测验来测试AI,它不是为了这个而被设计出来的。
这个合理一些,但是讯飞到底是何方神圣
把题目翻译成英文Gemini的分会不会更高点