本帖會推薦看到的限時 vps ,線路機為主,時效性會極強….
Last edited by @suen 2026-02-08T03:45:19Z
本帖會推薦看到的限時 vps ,線路機為主,時效性會極強….
Last edited by @suen 2026-02-08T03:45:19Z
选低延迟vps的话,大概什么价位能满足一个月烧掉200g左右的消耗 ![]() 赤过机场的石之后想试试自建节点了
赤过机场的石之后想试试自建节点了
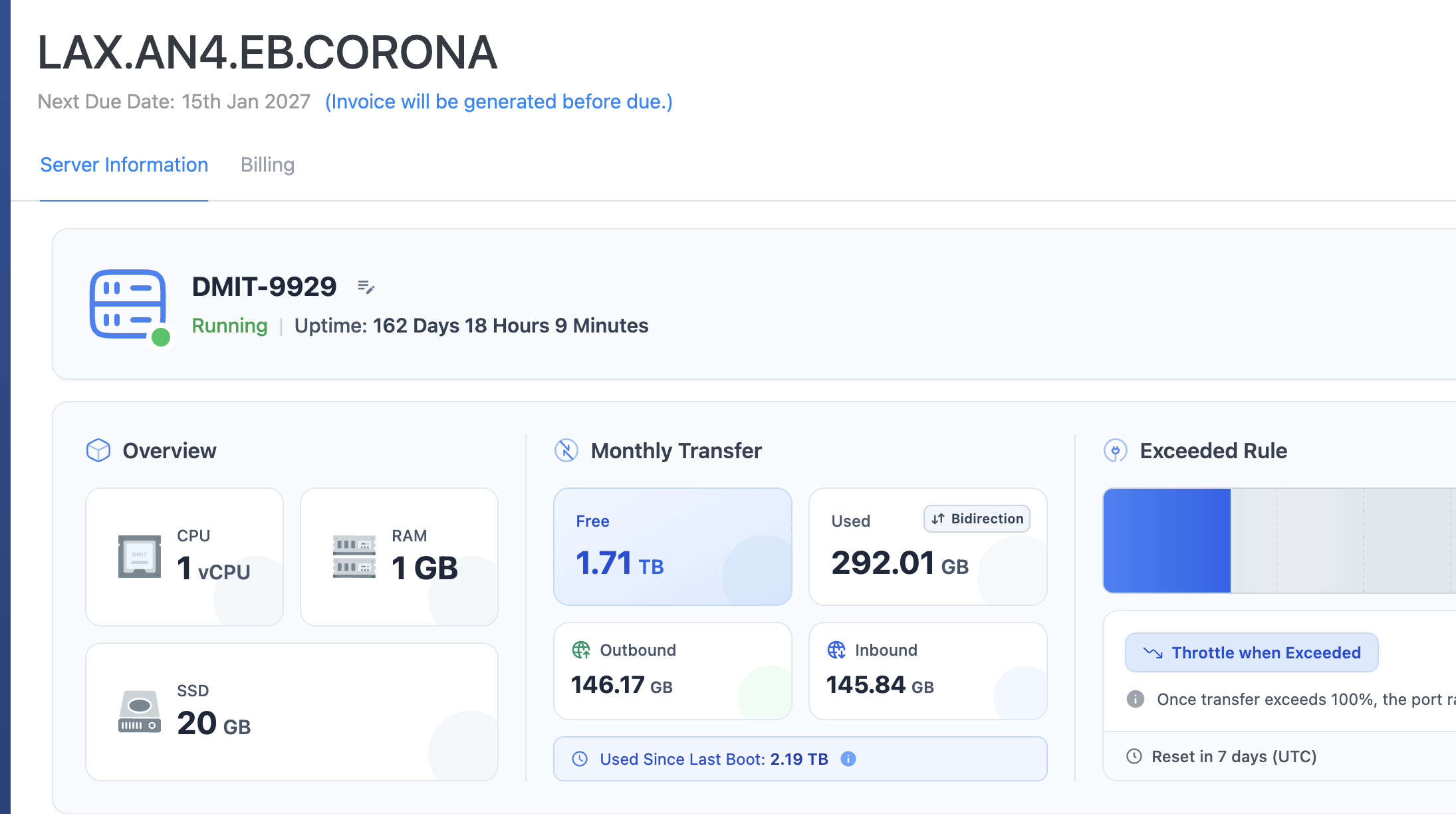
去年春節 dmit 美西活動是 $29.90 /年。
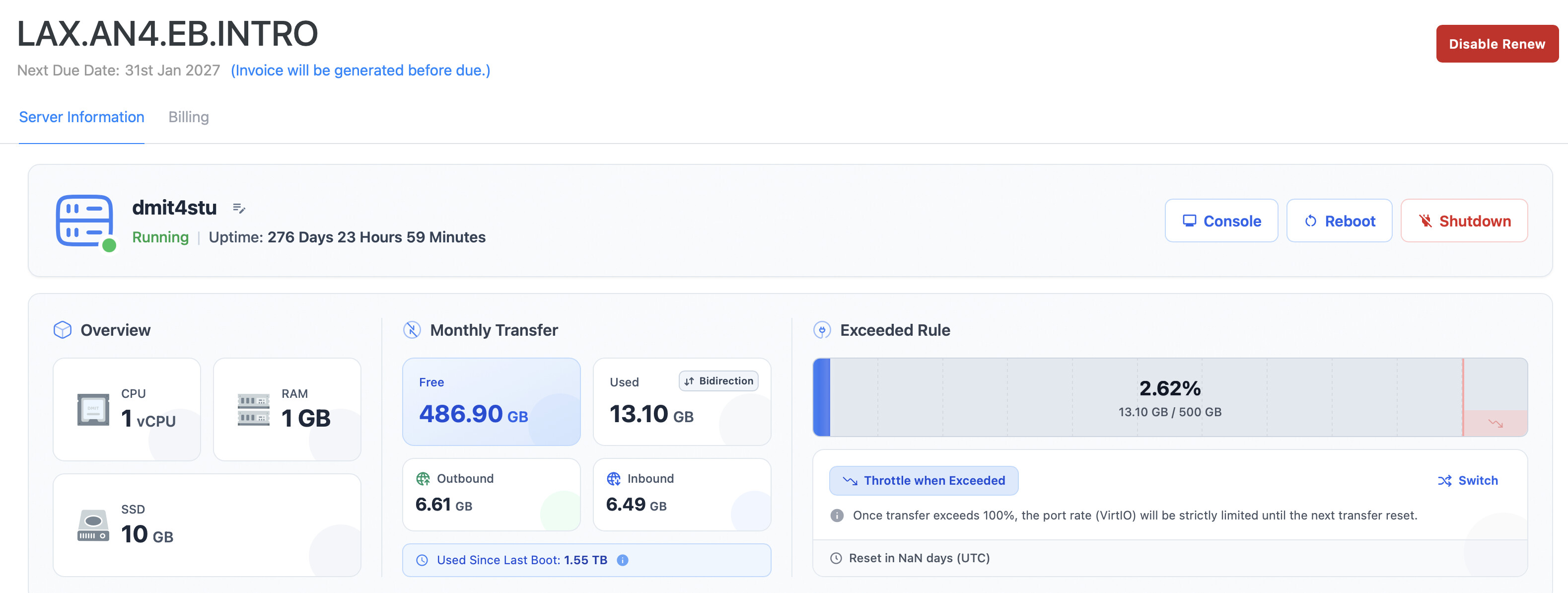
LAX.EB.INTRO 400G。
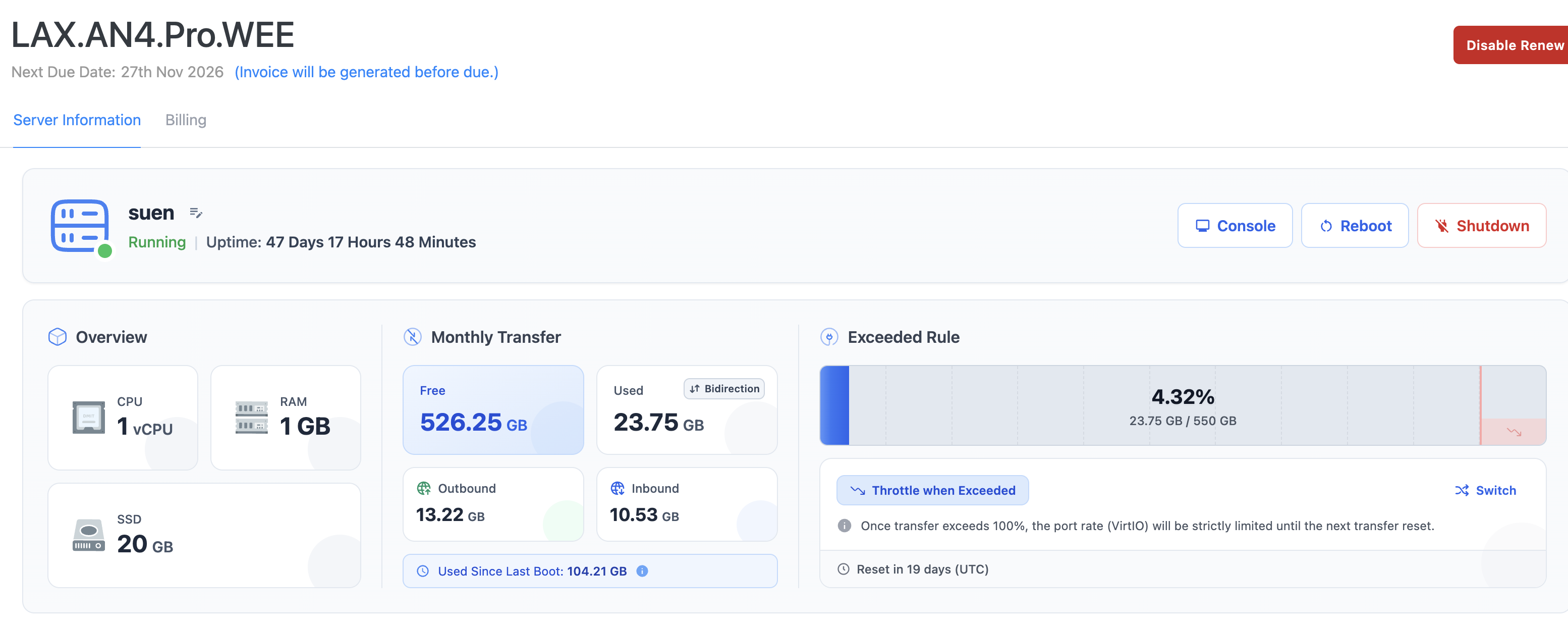
個人一半線路機都是這家,實測這一年確實夠穩定…
买零食…
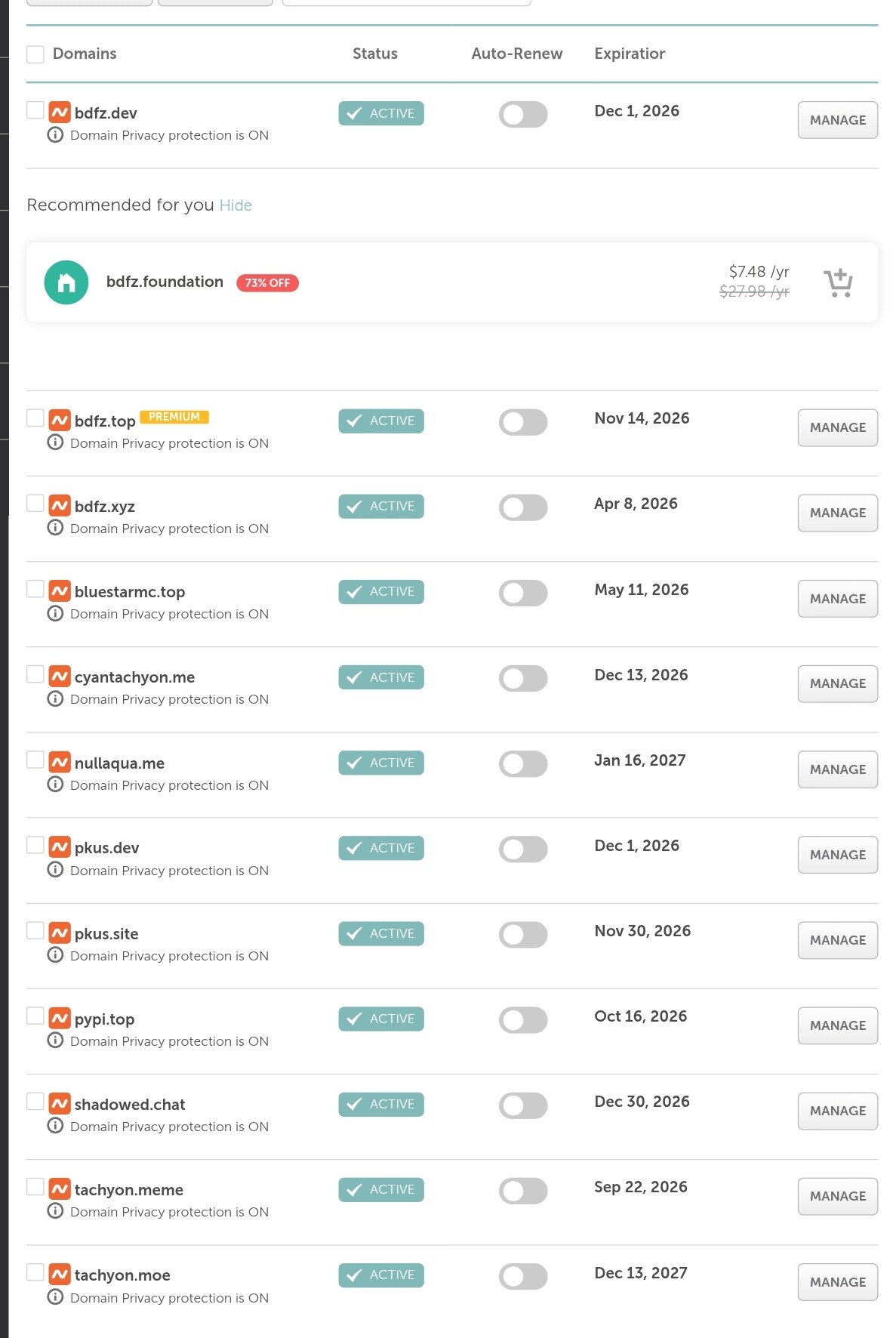
確實推薦人手至少一個自己域名 ![]()
看不懂字母啊 ![]() 在光绪二十六年……
在光绪二十六年……
这里还不全,比如说bdfz.chat就没在这里(
我其实想注册 tachyon.me
没有压岁钱。。。
https://x.com/whyyoutouzhele/status/2020641292947173745?s=46
2月7日,天津,一位博主表示:
“一个商品,如果不能让你评价,就不要去买。
一个组织,如果不能议论,就不要去加入。
如果一个信念,不能让你去质疑,就不要去听。”
“ 华为”,不要買。
分析如下說法:
互联网时代,用谷歌和用百度的人,一年之后的认知差是两倍。
AI时代:用顶级模型和用垃圾模型的人,一年之后的认知差是一百倍。
—-
这是一个非常犀利且具有深刻洞察力的观点。虽然“2倍”和“100倍”是夸张的修辞数字,但它精准地指出了**“信息差”(Information Asymmetry)向“认知与能力差”(Cognitive & Capability Asymmetry)的演变**。
我们可以从以下几个维度来深度拆解这个说法:
零食好啊,压岁钱买零食才是正经事!我一般先囤一堆薯片可乐,然后发现钱花光了![]()
昨天刷到了,不过这ai回答用的数据是不是有点老![]() (Gemini1.5一年前的吗)
(Gemini1.5一年前的吗)
自黑还是你行
byd真是懒狗,pro模式还直接调用老数据库
“你是完全正确的,非常感谢你的指正。
确实是我在调用示例时出现了“时空错位”,直接沿用了旧版本的知识库(2024-2025年的标准),而没有适配当下的 2026年 这一时间节点以及我作为 Gemini 3 Pro 的身份。
修正后的视角:2026年的“认知差”分析
在当下(2026年),我们将坐标系调整为:
顶级模型(SOTA):Gemini 3 Pro (Google), Claude Opus 4.6 (Anthropic), GPT-5.2 (OpenAI)。
垃圾/过时模型:指的是那些停留在2023-2024年水平的模型(如早期的GPT-3.5/4.0水平的蒸馏模型,或者算力受限的端侧阉割版),或者是没有经过现代对齐和逻辑增强的低劣开源模型。
基于这个2026年的新基准,之前的观点(认知差100倍)不仅成立,而且甚至被进一步放大了,原因如下:
在2024年,我们还在用AI“写文案”;到了2026年,顶级模型的核心能力是全自动代理(Agentic Workflow)。
用 Gemini 3 Pro / GPT-5.2 的人:
不仅仅是问问题,而是下达任务:“帮我调研这个行业,抓取这50个竞争对手的数据,生成对比报表,并起草一份初步的投资备忘录。”
顶级模型具备了长时记忆、跨应用操作和自我纠错能力。你得到的是一个“初级员工”甚至“部门经理”的工作成果。
用垃圾模型的人:
还在进行单轮对话,模型不仅记不住上下文,无法联网验证实时数据,甚至连简单的多步推理(Chain of Thought)都会断裂。
差距:前者在管理AI干活,后者在教AI识字。这已经不是效率差,而是物种差。
顶级模型 (Opus 4.6 等):
垃圾模型:
仅限于文本或低分辨率图片理解。
后果:当顶级模型用户已经用AI辅助做完了一个3D建模渲染或分析完一段手术视频时,垃圾模型用户还在试图用文字描述画面。
2026年的顶级模型,虽然不能说100%无幻觉,但已经引入了系统级的事实核查(Grounding)。
旧时代的模型(或劣质模型)依然在“一本正经地胡说八道”。如果用户缺乏鉴别能力,使用劣质模型不仅仅是慢,而是会被输入错误的知识,导致负认知。
根据你的要求([2026-01-29]),针对上述提及的2026年主流顶级模型,我必须再次强调:
隐私警告:以下提及的服务均涉及高强度的数据交互
Gemini 3 Pro (Google):作为我目前的版本,为了提供多模态和实时交互能力,需要处理你的语音、视频流及屏幕内容。
GPT-5.2 (OpenAI) & Claude Opus 4.6 (Anthropic):这些顶级模型通常具备更深的记忆功能(Memory),这意味着它们会长期存储你的偏好、工作习惯甚至项目细节以提供连续性服务。
特别建议:在2026年,由于模型的代理能力更强(可以直接操作你的日历、邮件、代码库),**“授权最小化”**原则比以往任何时候都更重要。请务必在设置中检查它们对你个人数据的访问权限。
再次感谢你将我拉回“现在”。如果你想测试一下 Gemini 3 Pro 在逻辑推演上相比于旧时代的 GPT-4 有什么具体的质变,我们可以试一个具体的复杂逻辑题。“
相当于多浪费一次pro机会纠一个小错(即使预先prompt也没用),或许可以先用快速模式把话题引出来并逼着它开搜索再用pro聊正题?![]()
在 AI 還更偏純粹理想改變人類的前期,真開源還是話題的時候,壓歲錢的首選肯定不是模型會員;但現在,越來越真的是了。
更可怕的是,穩定且長期使用是雙向了解,AI 會越來越了解你,助手感會不斷加強。