
目前科技公司通常使用GPU集群进行大语言模型推理,但GPU的显存成本高昂,产能受限,能耗成本也不容小觑。近日,AI芯片初创公司Taalas为了提升大模型每秒能生成的token数量(TPS),使用硬连线(hard-wired)技术,直接将大模型的权重以DRAM级密度刻录到硅芯片上,实现存储与计算融合,克服了系统中数据通信开销,大幅提升芯片TPS。他们推出的首款产品HC1采用台积电6纳米制程,芯片面积高达815平方毫米,服务器功耗仅2.5千瓦,且支持LoRA微调。
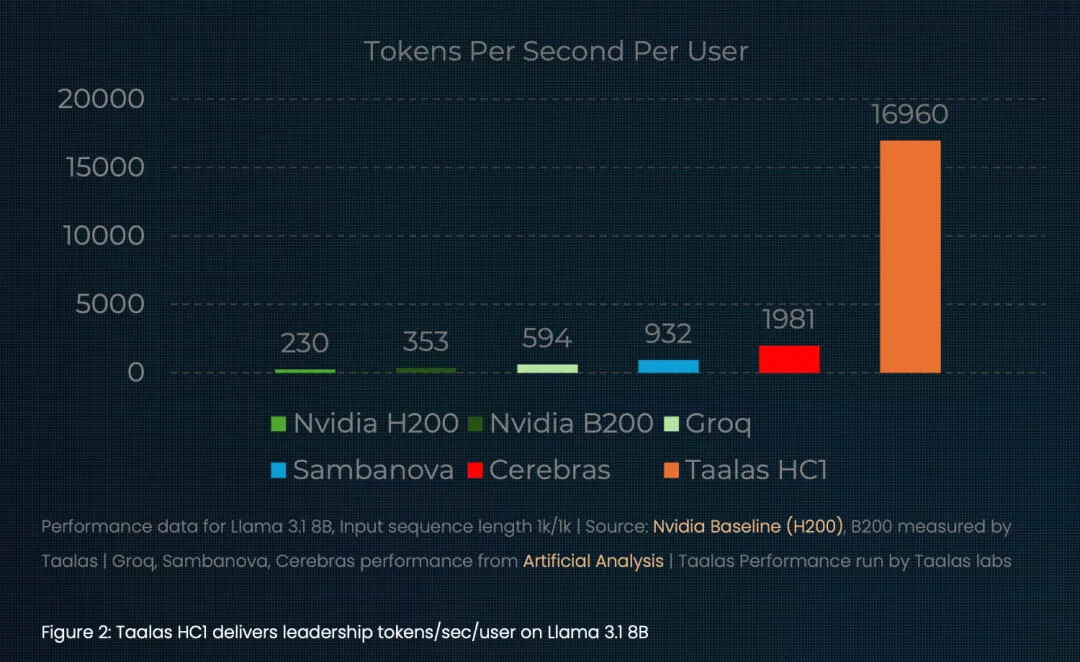
当Taalas将Meta的Llama 3.1 8B模型集成到HC1上时,推理速度可达16960 TPS,约为英伟达B200的48倍。Taalas的芯片也可以组成集群,运行更大的模型。据Taalas称,他们已经通过30芯片的配置实现了DeepSeek-R1的推理运行,速度可达12000 TPS。
为了适应AI模型的快速发展,Taalas开发了一个平台,可将任何AI模型转化为定制芯片。接受一个全新的模型后,只需要2个月就能实现定制硬件。这样的定制芯片在运行AI模型时,速度比通用GPU快1个数量级,且成本、功耗更低。(wccftech.com)