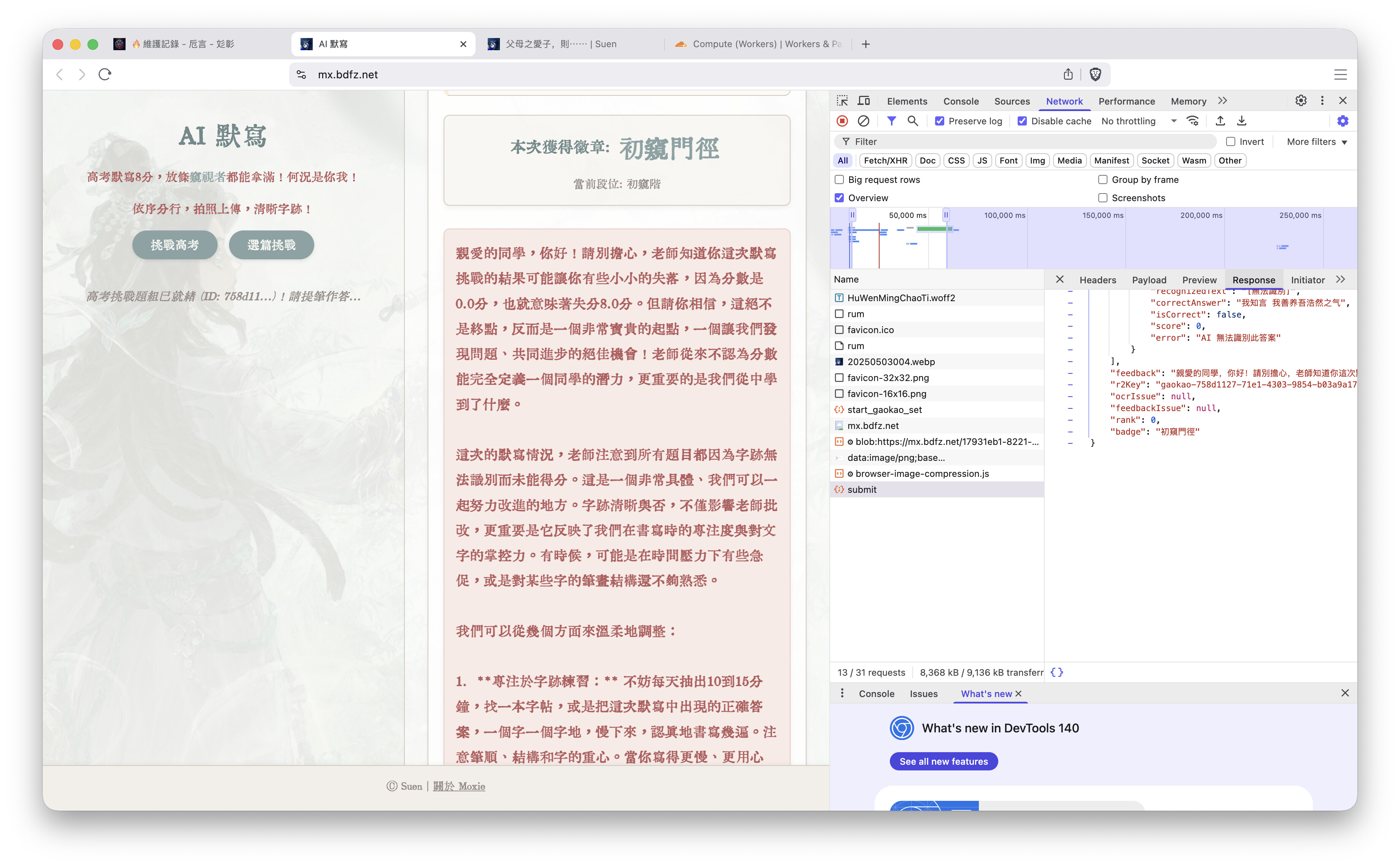
我这边也是极其的慢
剛開了CF,現在關了看看。
2 Likes
如果不挂上的话,加载相当慢,家就在学校附近,用的联通的宽带,好晚了懒得折腾了,先大致描述下我的情况
现在不在学校不清楚,明天试试,今天白天听到说论坛遇到了点小问题,但刚好今天白天忙没上线······
2 Likes
等我加個中轉⋯⋯
1 Like
調整線路,論壇會暫時不可訪問。
1 Like
校网环境不明,目前家庭网络环境依旧是10s左右的加载,并且每个功能点完都需要等待好久才有响应。太困了顶不住了,先休息了:(
明天如果有空我可以串流下家里的机子,看看状况如何,是否有好转
2 Likes
校网可用,正常
1 Like
1 Like
我電腦為什麼會只讀。。。不讓登錄
1 Like
多次遷移機房,域名切換了多次 IP,會有緩存,清掉緩存就好了。
2 Likes
日誌更新
1 Like
測試圖片地址。
更新說明:
昨日起出現用戶名密碼正確但提示“請稍候登錄”故障,已修復。
Summary
Awesome — glad it’s fixed. Here’s a clean, redacted, blog-style write-up you can post, plus I’ve saved the troubleshooting playbook to memory so I’ll recall it first next time.
Fixing “Please try again later” logins on Discourse behind a reverse proxy
TL;DR
A Discourse site running behind an Nginx reverse proxy (no Cloudflare proxy enabled) kept showing “please try again later” on login. Root cause was client IP not reaching the app and login rate-limit keys piling up. We fixed it by ensuring the proxy forwards real client IPs, teaching Discourse to trust that proxy, enabling real_ip inside the container, and doing a few hygiene/SSL hardening steps. Result: Rails sees the true client IP, rate limits behave correctly, and logins succeed.
Environment (sanitized)
- Front proxy: Nginx on a VM (<FRONT_PROXY_IP>), proxying https:// to origin.
- Origin: Discourse’s official Docker container on another VM (<ORIGIN_IP>).
- Cloudflare: DNS-only (gray cloud) during the incident.
- Object storage: Cloudflare R2 (endpoint format https://<R2_ACCOUNT_ID>.r2.cloudflarestorage.com) with path-style and checksums.
Symptoms
- Users with correct credentials got a generic “please try again later” at login.
- Browser DevTools showed repeated requests but no clear auth error.
- On the origin, Nginx access logs and Rails logs showed requests coming from the proxy IP, not end-user IPs.
- Redis contained many login-related rate-limit keys.
Root causes
- Real client IP didn’t reach Discourse
- The front proxy wasn’t reliably adding X-Forwarded-For to upstream requests (a duplicate/old virtual host was likely in use).
- Inside the Discourse container, Nginx wasn’t configured to “trust” the proxy and map the forwarded address to the real client IP.
- Rate limiting triggered on the proxy IP With every login attempt appearing to come from the same IP, Discourse’s rate limiter kicked in, yielding the “try again later” message.
- (Secondary) SSL upstream verification and misc. config gotchas
- Upstream TLS was enabled without the proper trusted CA bundle, which can fail verification.
- A mistaken reload command and a few minor config details (e.g., Connection header) needed cleanup.
What we changed
1) Make the front proxy forward real client IPs
Ensure these headers are set in the front proxy Nginx for the active vhost (after removing any duplicate vhost files):
# On <FRONT_PROXY_IP>, server for <DOMAIN>
proxy_set_header Host $host;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Real-IP $remote_addr;
# Strict TLS upstream (proxy to origin by IP but verify SNI/hostname)
proxy_ssl_server_name on;
proxy_ssl_name <DOMAIN>;
proxy_ssl_trusted_certificate /etc/ssl/certs/ca-certificates.crt;
proxy_ssl_verify on;
proxy_ssl_verify_depth 3;
# Discourse-friendly proxying
proxy_http_version 1.1;
proxy_buffering off; # long-polling/message bus
proxy_read_timeout 300s;
proxy_send_timeout 300s;
Sanity check: remove duplicate vhosts so only one server_name ; is enabled.
2) Teach Discourse to trust the proxy
In containers/app.yml, set:
env:
DISCOURSE_TRUSTED_PROXIES: |
<FRONT_PROXY_IP>
(If you already added it, you’re good. Requires a rebuild to take effect.)
3) Enable
real_ip
inside the container
Create /etc/nginx/conf.d/10-realip.conf inside the Discourse container:
real_ip_header X-Forwarded-For;
set_real_ip_from <FRONT_PROXY_IP>;
real_ip_recursive on;
Optional XFF debug log to prove the headers are arriving:
# /etc/nginx/conf.d/11-logxff.conf
log_format xff '$remote_addr - $host [$time_local] "$request" '
'$status $body_bytes_sent xff="$http_x_forwarded_for" xri="$http_x_real_ip"';
access_log /var/log/nginx/access_xff.log xff;
4) Clear stale login rate-limit keys
Inside the app container:
redis-cli --scan --pattern 'rate_limit:*login*' | xargs -r redis-cli DEL
5) Persist the fix across rebuilds
Add a second - exec block under your existing hooks: after_code: in containers/app.yml to drop those two conf files at build time (sanitized):
hooks:
after_code:
- exec:
cd: $home/plugins
cmd:
- git clone https://github.com/discourse/docker_manager.git
# ...your other plugins here...
- exec:
inline:
- |
cat >/etc/nginx/conf.d/10-realip.conf <<'CONF'
real_ip_header X-Forwarded-For;
set_real_ip_from <FRONT_PROXY_IP>;
real_ip_recursive on;
CONF
- |
cat >/etc/nginx/conf.d/11-logxff.conf <<'CONF'
log_format xff '$remote_addr - $host [$time_local] "$request" $status $body_bytes_sent xff="$http_x_forwarded_for" xri="$http_x_real_ip"';
access_log /var/log/nginx/access_xff.log xff;
CONF
(You don’t have to rebuild immediately; the running container already has the live fix. This just future-proofs it.)
6) SSL verification sanity check
Confirm the origin really serves a certificate for :
openssl s_client -connect <ORIGIN_IP>:443 -servername <DOMAIN> -verify_return_error </dev/null \
| sed -n '/subject=/p;/issuer=/p;/Verify return code/p'
# Expect: Verify return code: 0 (ok)
7) Security hardening
- Restrict the origin to accept ports 80/443 only from the front proxy IP (example with UFW):
sudo ufw default deny incoming
sudo ufw allow from <FRONT_PROXY_IP> to any port 443 proto tcp
sudo ufw allow from <FRONT_PROXY_IP> to any port 80 proto tcp
sudo ufw enable
- Lock down containers/app.yml permissions:
sudo chmod o-rwx /var/discourse/containers/app.yml
8) R2/S3 correctness (sanitized)
Key bits that prevented storage surprises:
env:
DISCOURSE_USE_S3: "true"
DISCOURSE_S3_ENDPOINT: "https://<R2_ACCOUNT_ID>.r2.cloudflarestorage.com"
DISCOURSE_S3_FORCE_PATH_STYLE: "true"
DISCOURSE_S3_REGION: "auto"
DISCOURSE_S3_BUCKET: "<UPLOADS_BUCKET>"
DISCOURSE_S3_BACKUP_BUCKET: "<BACKUPS_BUCKET>"
DISCOURSE_S3_ACCESS_KEY_ID: "<REDACTED>"
DISCOURSE_S3_SECRET_ACCESS_KEY: "<REDACTED>"
AWS_REQUEST_CHECKSUM_CALCULATION: "WHEN_REQUIRED"
AWS_RESPONSE_CHECKSUM_VALIDATION: "WHEN_REQUIRED"
DISCOURSE_HOSTNAME: "<DOMAIN>"
DISCOURSE_FORCE_HOSTNAME: "true"
Validation checklist
- Origin Nginx access (debug) log shows xff=“<REAL_CLIENT_IP, <FRONT_PROXY_IP>>” and $remote_addr equals <REAL_CLIENT_IP>.
- Rails production.log lines say Started GET … for <REAL_CLIENT_IP>.
- Login flow: POST /session returns 200/302 (not 429).
- Strict TLS upstream: Verify return code: 0 (ok) in openssl s_client.
- No conflicting vhosts on the front proxy (nginx -T shows a single active vhost for ).
Potential future adjustments
- If you later enable Cloudflare proxy (yellow cloud):
- On the front proxy, switch to real_ip_header CF-Connecting-IP and trust CF’s IP ranges.
- In Cloudflare, add rules to skip WAF/challenges and bypass cache for POST /session and /u/*/login.
- Tune rate limits only after real IP is fixed: modest increases for max logins per ip per minute/hour, etc.
- Observability: keep the access_xff.log formatter around (or a hidden __headers location) for quick header sanity checks.
Lessons learned
- Discourse’s login throttling is IP-based; one missing header can make everyone look like the same source.
- When in doubt, verify the full chain: front proxy headers ➜ container real_ip ➜ Rails Started … for ….
- Make fixes rebuild-proof (commit them to app.yml hooks) and lock down your origin.
If you want this as a Markdown file, say the word and I’ll hand you a downloadable copy.
Saved to memory: I’ve stored a summarized “reverse-proxy Discourse login/rate-limit playbook” (no secrets) and will recall it first before troubleshooting similar issues.
1 Like
老师为啥ai老死机啊 对话多长会容易死机
1 Like
最近幾天Google不怎麼穩定⋯⋯
2 Likes
that’s too true - the API was like the model is overloaded all day![]() - Gemini 2.5 Pro’s just gone viral these days; is it possible to add a fallback plan using 2.5 Flash or Flash-Lite? @suen
- Gemini 2.5 Pro’s just gone viral these days; is it possible to add a fallback plan using 2.5 Flash or Flash-Lite? @suen
1 Like
差不多都。
估計Gemini 3要來了。
3 Likes
给我暴打GPT
2 Likes
An update of the model on sites like mx.bdfz.net is probably needed - Google doesn’t redirect models/gemini-2.5-flash-preview-04-17 (which Moxie currently uses) to the latest model.
2 Likes